안녕하세오 서루태에오~

지난시간에는 plot함수를 이용해서 그래프를 그려보았어요.
이번에는 다른 그래프도 그려볼게요.
자주 쓰이는 그래프로는 boxplot이라고 불리는 그래프 형태에요
박스 플롯으로 표현하는 코드를 한번 적어볼게요!
import csv
import matplotlib.pyplot as plt
import koreanize_matplotlib
f = open('/content/seoul.csv', 'r', encoding='euc-kr')
data = csv.reader(f)
header = next(data)
# 1) 결측치를 제외한 데이터만 시각화
# 1월달 최고 기온, 8월달 최고 기온 담을 리스트 변수 선언
jan_temp = []
aug_temp = []
# 2) 01월, 08월의 최고기온 데이터 추출
for row in data:
# 3-1) 결측치 처리
if row[-1] != '':
# 3-2) 01월달 데이터 추출
if row[0].split('-')[1] == '01':
jan_temp.append(float(row[-1]))
# 3-3) 08월달 데이터 추출
if row[0].split('-')[1] == '08':
aug_temp.append(float(row[-1]))
# 4) 01월, 08월에 대한 최고 기온 박스플롯 그리기
plt.title(f'서울의 1월,8월 최고기온 박스플롯')
plt.boxplot([jan_temp, aug_temp])
plt.xticks([1,2],['01월 최고기온','08월 최고 기온'])
plt.show()
f.close()
아래 동글뱅이들은 이상치라고 부르며
평균값을 방해, 통계치를 방해함.
인구 공공데이터를 활용한 인구구조 분석
저와 함께 인구구조 분석 코드를 만들어봐요
차근차근 스텝을 밟아가 보자구요!
데이터 다운로드
먼저 행정안전부에서 연령별 인구현황을 살펴봅시다!
https://jumin.mois.go.kr/index.jsp
주민등록 인구통계 행정안전부
jumin.mois.go.kr

다음과 같은 화면에서
조회기간을 19년 2월의 자료만을 가져왔어요
남녀 구분은 체크해제 해주시고 '전체읍면동현황'으로 'csv파일'을 다운로드 해줄게요
코랩에 파일을 업로드하기전에
notepad++나 메모장,
맥 유저라면 텍스트 편집기 또는 Atom을 이용해서 데이터 파일을 확인 먼저 해주세요
저는 맥이라서 Atom을 이용해볼게요

지금 보시면 글자가 깨져있죠?
저 말고도 이런분들이 계실거에요.
그럴때는 Encoding 타입을 확인 해 주세요

UTF-8이죠? 지난 글에서 말했던 것처럼
UTF-8은 한글이 깨져서 표현되기 때문에
EUC-KR로 바꿔주세요


EUC-KR로 바꿔주니 깔끔해졌어요!
데이터 확인하기
import csv
#1)파일 읽기
f=open('/content/drive/MyDrive/Colab Notebooks/source/201902_201902_연령별인구현황_월간(1).csv','r')
data = csv.reader(f)
for row in data:
print(row)다음처럼 입력해주시면 한줄씩 파일데이터를 출력해 줄거에요

다음과 같이 csv파일을 프로그램 내에서 출력할 수 있겠지요~
이 중에 원하는 지역만 출력할 수 있을까요?
if문을 이용해서 특정 지역이 있는 리스트만을 뽑아내면 할 수 있어요
전체 코드중 일부만 적어볼게요
#2)데이터 한줄씩 체크
for row in data:
#3) 신도림 지역의 정보만 담기
if '신도림' in row[0]:
~~~~~~~보면 row[0]의 값이 지역명이 담긴 인덱스니까
in 연산자를 이용해서 '신도림'이 들어있는 인덱스를 찾아서
신도림 데이터만 사용하면 될거에요
import csv
import matplotlib.pyplot as plt
import koreanize_matplotlib
f=open('/content/drive/MyDrive/Colab Notebooks/source/201902_201902_연령별인구현황_월간(1).csv','r')
data = csv.reader(f)
header = next(data)
result = []
#2)데이터 한줄씩 체크
for row in data:
#3) 신도림 지역의 정보만 담기
if '신도림' in row[0]:
#4) 0~99세 인구수 담기
for i in row[3:]: # 0세 인덱스부터 출력
if i == '': # 깡통 데이터 제외
continue
result.append(int(i.replace(',',''))) # 1,234같은 1000이상의 데이터 변환
#5) 연령 별 인구수 시각화
plt.title('신도림의 연령 별 인구 구조')
plt.style.use('ggplot')
plt.plot(result)
plt.show()csv 파일 위치는 각자 상이하니 참고해주세요

이렇게 신도림의 0세부터 99세까지의 데이터가 출력됩니다!
이런식으로 데이터를 시각화 하면 어느 구간의 인구가 많은지 한눈에 알 수 있어요
이제 조금 더 응용해서 사용자에게 데이터를 입력받을 수도 있겠죠?
import csv
import matplotlib.pyplot as plt
import koreanize_matplotlib
f=open('/content/drive/MyDrive/Colab Notebooks/source/201902_201902_연령별인구현황_월간(1).csv','r')
data = csv.reader(f)
header = next(data)
# 인구 구조 결과를 담을 리스트 선언
result = []
si = input("지역을 입력해주세요 : ")
dong = input("동네명(동) 입력해주세요 : ")
#2)데이터 한줄씩 체크
for row in data:
#3) 시와 동의 정보 담기
if si in row[0] and dong in row[0]:
#4) 0~99세 인구수 담기
for i in row[3:]:
if i == '':
continue
result.append(int(i.replace(',','')))
#5) 연령 별 인구수 시각화
plt.title(f'{dong}의 연령 별 인구 구조')
plt.style.use('ggplot')
plt.plot(result)
plt.show()
f.close()
입력한 시와 동이 모두 들어간 데이터셋을 불러오는거에요
Pandas 라이브러리
드디어 데이터 분석의 꽃! pandas에 대해서 알아볼게요
01 데이터 분석 기초 - 데이터 파악하기, 다루기 쉽게 수정하기
데이터 파악하기
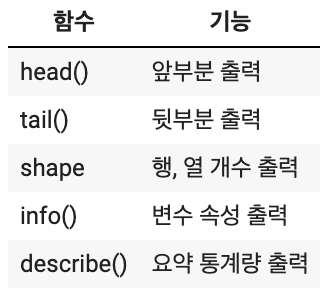
먼저 데이터를 파악에 쓰이는 함수들을 소개할게요
mpg 데이터 불러오기
import pandas as pd
mpg = pd.read_csv('/content/sample_data/mpg.csv', encoding='utf-8')pandas를 import하고 pd라고 이름지어줍시다
(무조건 pd라고 써야해요!)
.read_csv 메소드를 사용해서 mpg라는 데이터 파일을 불러와줄게요
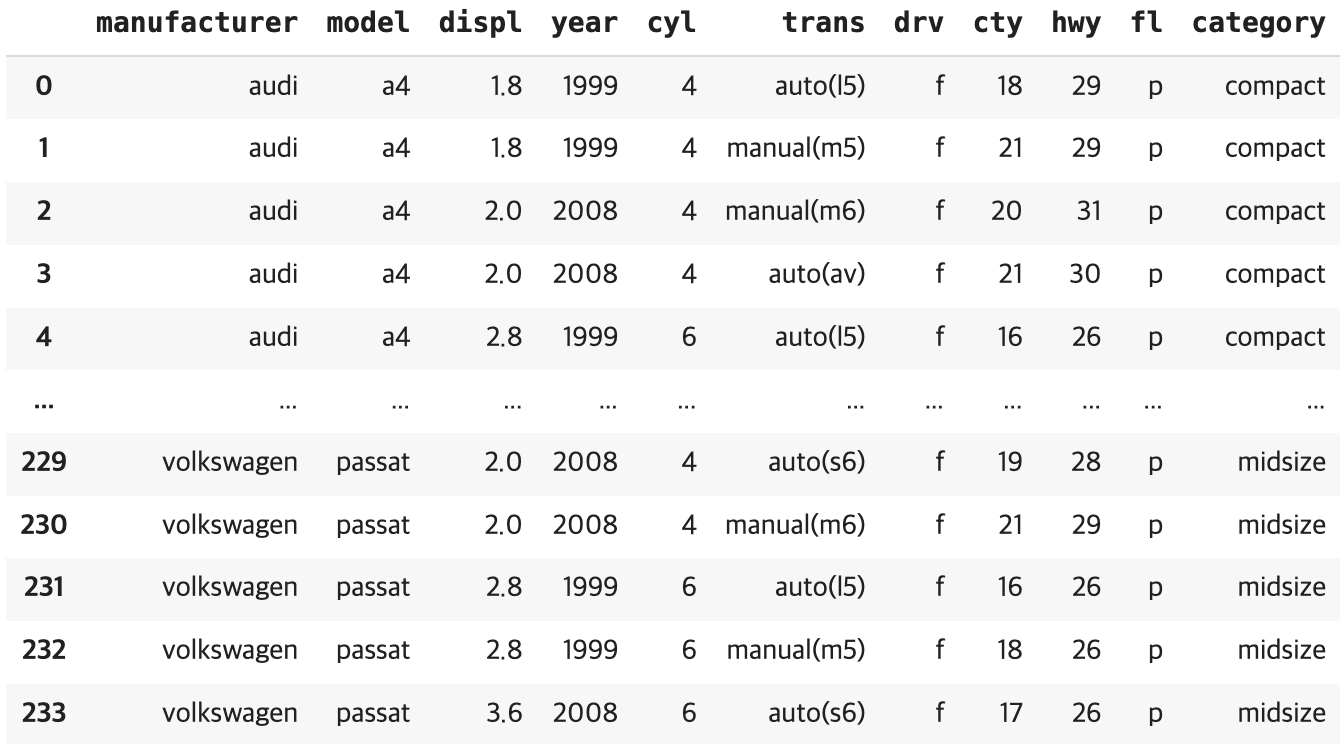
아쉽게도,,, csv파일을 공유해 드릴수는 없어요...😢
전에 소개해드린 데이터 분석용 자료 사이트에서 가져와서 실습하시는걸 추천드릴게요
pandas 라이브러리를 사용하면 리스트를 한 줄씩 표기하던 지난 방식과는 다르게
데이터프레임이라는 자료구조로 표시가 된답니다!
앞으로 데이터프레임을 df로 줄여서 표현할게요
mpg 데이터 파악하기

head 메소드의 기본은 상위 5개를 출력하고
매개변수에 적은 수만큼 위에서 출력해줘요
ex) .head(10) => 상위 10개 출력

head와 반대개념을 가진 tail 메소드에요
하위 n개를 출력해주고 마찬가지로 기본값은 하위 5개 출력이에요
함수 vs 메서드 vs 어트리뷰트
프로그래밍에서 많이들 헷갈리지만 기초적인 내용을 가져왔어요
#1) 내장함수 : import 없이 사용가능한 함수
sum(mpg['year'])
#2) 패키지 함수 : import 하여, 사용할 수 있는 함수
pd.read_csv('/content/sample_data/mpg.csv')
#3) 메서드 : 객체를 통해서 사용할 수 있는 기능
mpg.head()
#4) attribute : 객체의 속성 / 괄호없이
mpg.shape이것만 알고 있다면 당신도 기본기 마스터!
컬럼명 바꾸기
#아무것도 출력 안되면 바로 반영, 출력값이 존재하면 바로 반영 아님 어딘가에 담아둬야 해요
df_new = df_new.rename(columns = {'manufacturer':'manufact'}) #manufacturer를 manufact로 변경여기서 아주아주 중요한 개념이 들어있어요
renmane 메소드를 이용해서 컬럼명을 바꾸고싶은데
df_new라는 함수에 다시 담아두지 않으면 반영되지 않아요!
반영 여부는 메소드만 사용했을때 return값이 존재하는지를 살펴보면 된답니다!

위처럼 manufacturer에서 manufact로 컬럼명이 바뀌었어요! ㅎㅎ
파생변수 만들기
쉽게 말해서 주어진 칼럼변수들로 새로운 변수를 만들어내는 것이에요
'cty'라는 도시주행연비와 'hwy'라는 고속도로주행연비를 더해서
평균연비를 만들어 볼게요
#통합 연비 계산을 어떻게 할 것인가?
#통합 연비 = (도시 연비 + 고속도로 연비) /2 도시와 고속도로의 평균값
df_mpg['total'] = (df_mpg['cty'] + df_mpg['hwy']) / 2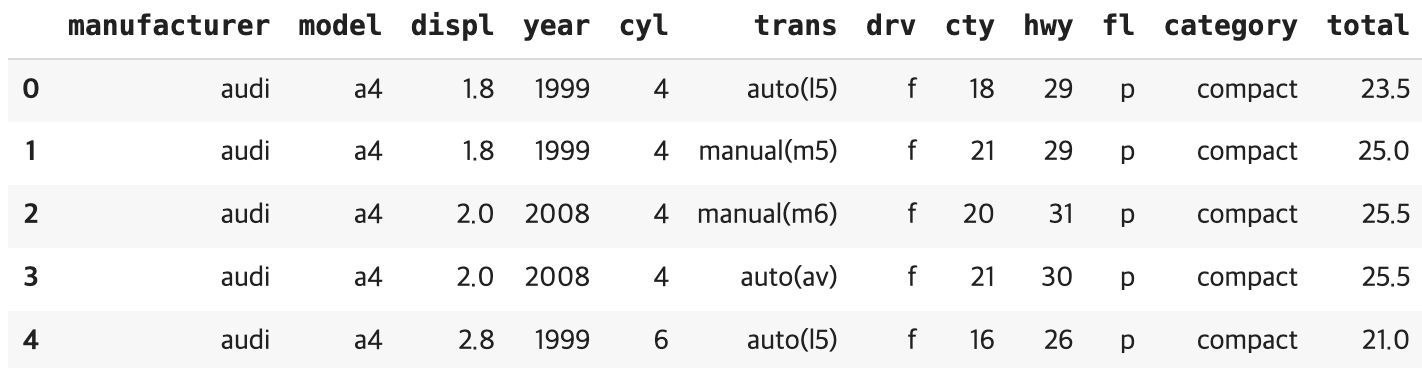
잘 보면 total 변수가 새로 생겼죠?
평균값이 잘 들어간 모습을 확인할 수 있어요
이제 조건을 붙여서 변수를 만들어볼게요
먼저 total의 평균치를 .describe 함수로 얻어줄게요
#평균 연비들의 평균을 구하기
df_mpg['total'].describe() #요약 통계량
=> 20.14957264957265러프하게 약 20정도라고 생각하고
연비가 20이상이면 'pass'
20보다 낮으면 'fail'
이라는 값을 변수로 만들어줄게요
import numpy as np
# total 값이 20 이상이면 pass, 20 미만이면 fail
df_mpg['test'] = np.where(df_mpg['total'] >= 20,'pass','fail') #np.where(조건 ,True일떄,False일때)
#if문의 간략화여기서 새로운 개념이 등장해요
바로 'numpy'랍니다
이전 글에서도 소개했듯이 numpy는 연산에 최적화된 함수들을 가지고 있어요
np의 where함수를 이용해서 'total'값이 20이상이면 'pass', 아니면 'fail'을 매겨줄게요
df_mpg['test'].value_counts()
=> test
pass 128
fail 106
Name: count, dtype: int64그리고 value_counts() 메소드로 test의 결과값의 분포를 한눈에 볼 수 있어요
pass가 더 많다는게 한눈에 보이죠?
이걸 막대그래프로 그려볼게요
df_mpg['test'].value_counts().plot.bar(rot = 0) # 축 이름을 수평으로 만들기
파이차트로 원형 그래프를 그릴수도 있답니다!
df_mpg['test'].value_counts().plot.pie(autopct='%.1f%%') # 퍼센트로 적어주기
자유자재로 데이터 가공하기
여기서부터가 정말 중요해요!!
우리가 하고자 하는 데이터 분석을 위해선
앞으로 정말 많이 쓰일 내용이랍니다!
데이터 전처리

추가로 하나 더 하자면,
df_mpg['category'].unique() #카테고리에 종류가 뭐가 있는지 확인하는 메소드 .unique
=>array(['compact', 'midsize', 'suv', '2seater', 'minivan', 'pickup',
'subcompact'], dtype=object).unique() 메소드는 변수안에 값들의 종류를 뽑아내줍니다
예시를 들어볼게요
df_mpg.query("category != 'minivan'")이러면 minivan을 제외한 데이터가 출력되겠죠?

.query() 메소드는 이렇게 조건을 걸어 그 조건에 맞는 행을 추출하는 메소드랍니다
필요한 변수만 추출하기
df_mpg[['category']] # 차종만 추출 -> 데이터 프레임 자료 구조로 추출
여기서 핵심은 대괄호가 두개라는 것이에요
물론 여러개도 추출가능해요
df_mpg[['category','model','year']]
이렇게 자신의 입맛대로 데이터를 뽑아낼 수가 있답니다~
컬럼 제거하기
df_mpg.drop(columns = ['total','category']) # category,model 컬럼 제거.drop() 메소드를 이용해서 total과 category 컬럼을 제거하는 코드에요.
한 개는 물론 여러개의 컬럼을 제거할 수 있어요
데이터의 정렬
#연식 기준으로 데이터 정렬 -> 기본 오름차순 (작은것에서 큰것으로 정렬) -> 연식이 오래된 순으로 확인 가능
df_mpg.sort_values('year').sort_values 메소드로 오름차순으로 year 데이터를 정렬해 줬어요

year부분이 정렬된 걸 확인 할 수 있어요
.sort_values 메소드는 기본값이 오름차순이라서
매개변수에 내림차순으로 지정해주면 손쉽게 반대로도 표현이 가능해요
#연식 기준으로 데이터 정렬 -> 내림차순 정렬 (작은것에서 큰것으로 정렬) -> 최신순으로 확인 가능
df_mpg.sort_values('year', ascending=False)ascending을 기본값인 True에서 False로 바꾸면
내림차순으로 정렬이 된답니다!
여러 컬럼을 한번에 정렬할 수도 있어요
#여러 기준을 데이터 정렬 -> 내림차순 정렬 (작은것에서 큰것으로 정렬) -> 최신순으로 확인 가능
df_mpg.sort_values(['year','category'], ascending=[False,True])year는 내림차순, category는 오름차순으로 정렬해줄게요

참 쉽죠? ㅎㅎ
파생 변수 추가
파생 변수를 추가하는 또 다른 방법을 알아볼게요
# df_mpg['total'] = (df_mpg['cty'] + df_mpg['hwy']) / 2
mpg = mpg.assign(total = (df_mpg['cty'] + df_mpg['hwy']) / 2)위 아래 코드의 실행값이 같아요. 둘 다 total이라는 변수를 추가하는 코드에요
하지만 .assign의 장점은 한번에 변수를 여러개 추가가 가능해요
mpg = mpg.assign(total2 = df_mpg['cty'] + df_mpg['hwy'], total3 = (df_mpg['cty'] + df_mpg['hwy'])*2)
mpg
보면 total에 이이서 total2 total3가 모두 들어가 있는걸 확인 할 수 있어요
그렇기에 .assign 메소드를 사용하는게 확장성에 용이하답니다!
오늘의 글은 여기까지!!
긴 내용 다 읽느라 고생하셨어요 ㅜㅜ
다음 글도 힘내서 함께 빡코딩! 해보아요!
오늘은 여기까지~~
안녕~
'ABC 부트캠프' 카테고리의 다른 글
| [9일차] ABC 부트캠프 - 데이터 분석 with Python (교통사고 데이터) (2) | 2024.07.04 |
|---|---|
| [8일차] ABC부트캠프 - 데이터 분석 with Python (실전 예제) (0) | 2024.07.03 |
| [6일차] ABC부트캠프 - 데이터 분석 with Python (matplotlib) (0) | 2024.07.01 |
| [5일차] ABC 부트캠프 - 파이썬 기초 #4 (재귀함수,내장 함수, 표준 라이브러리) (1) | 2024.06.28 |
| [4일차] ABC 부트캠프 - 파이썬 기초 #3 ( 제어문 & 연습 예제, 함수) (2) | 2024.06.27 |


