안녕하세요 서루태에오!

오늘도 힘내서 공부해 보자구요!
오늘은 도로교통공단에서 제공하는 사망 교통사고 데이터를 분석하고 시각화해볼게요
데이터 준비하기
https://www.data.go.kr/data/15070340/fileData.do
도로교통공단_사망 교통사고 정보_20221231
- 사망 교통사고에 대한 개별정보 제공(발생일시, 사고유형, 위치좌표 등)<br/>- 부상자수 = 중상자수 + 경상자수 + 부상신고자수<br/>
www.data.go.kr
이번 분석에 쓰이는 패키지들 임포트 해줄게요
패키지 설치
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import koreanize_matplotlib
import folium
import warnings
warnings.filterwarnings('ignore')
데이터 불러오기
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/source/도로교통공단_교통사고 정보_2019 (1).csv', encoding='euc-kr')제가 받은 파일위치라서
파일 위치만 수정해서 넣어주시면 돼요.
df.info()
=>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3233 entries, 0 to 3232
Data columns (total 23 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 발생년 3233 non-null int64
1 발생년월일시 3233 non-null int64
2 주야 3233 non-null object
3 요일 3233 non-null object
4 사망자수 3233 non-null int64
5 부상자수 3233 non-null int64
6 중상자수 3233 non-null int64
7 경상자수 3233 non-null int64
8 부상신고자수 3233 non-null int64
9 발생지시도 3233 non-null object
10 발생지시군구 3233 non-null object
11 사고유형_대분류 3233 non-null object
12 사고유형_중분류 3233 non-null object
13 사고유형 3233 non-null object
14 가해자법규위반 3233 non-null object
15 도로형태_대분류 3233 non-null object
16 도로형태 3233 non-null object
17 가해자_당사자종별 3233 non-null object
18 피해자_당사자종별 3233 non-null object
19 발생위치X_UTMK 3233 non-null float64
20 발생위치Y_UTMK 3233 non-null float64
21 경도 3233 non-null float64
22 위도 3233 non-null float64
dtypes: float64(4), int64(7), object(12)
memory usage: 581.1+ KB.info 메소드로 정보를 받아오면 ! 모든 데이터가 3233으로 '결측치 없이' 다 불러왔어요!😊
사망 교통사고 데이터 전처리
이제 전처리 과정이 필요해요.
지금 날짜데이터가 '발생년월일시'로 하나로 합쳐져 있기 때문에
여기서 '발생시간'을 빼와서 데이터를 쪼개줄게요
먼저 데이터를 복사하고,
accident_df = df.copy()
accident_df.head()발생년월일시 컬럼에서 시간 파생 컬럼 만들기
#사망 교통사고가 가장 많이 발생한 시간은?
# 발생년월일시 -> 시간 추출 (int값) -> 뒤에 두자리(00~23) -> 파생 컬럼으로 따로 분리
# 2019010121 -> 21 -> 분리 할 수 있는 키워드 없음 -> 문자열 슬라이싱
# 1) 문자열 슬라이싱 하고 싶으면 문자열로 타입 변경 (int형의 컬럼을 string 형변환)
accident_df = accident_df.astype({'발생년월일시':'string'})
accident_df.info()
=>
0 발생년 3233 non-null int64
1 발생년월일시 3233 non-null string
2 주야 3233 non-null object
3 요일 3233 non-null object보면 발생년월일시가 string으로 바뀌었고,
이걸 문자열 슬라이싱을 통해 시간을 떼줄게요
사소한 것 같지만 아주! 중요해요!
# 2) 시간으로 분리한 데이터를 발생시간 컬럼에 담기
accident_df['발생시간'] = accident_df['발생년월일시'].str[-2:]
accident_df['발생시간'].head()
=>
0 0
1 3
2 16
3 19
4 21보면 3시 16시 19시 등등..
잘 들어갔죠?
지금 시간 컬럼의 자료형은 str이기때문에 int로 바꿔줄게요
# 3) 발생시간 컬럼을 숫자 데이터 타입으로 변경
accident_df = accident_df.astype({'발생시간':'int'})
accident_df.info()
=>
22 위도 3233 non-null float64
23 발생시간 3233 non-null int64int로 잘 바뀌었죠~
발생년월일시 컬럼에서 발생년월일 파생 컬럼 만들기
이제 시간을 떼고 나머지 날짜만 들어있는 컬럼을 만들어줄게요
이 친구는 datetime 자료형으로 바꿔줄게요
to_datetime 함수를 써줄게요
# 발생년월일시(string) -> 발생년월일(날짜타입, datetime) 변경
accident_df['발생년월일'] = pd.to_datetime(accident_df['발생년월일시'].str[:-2],
format='%Y%m%d', errors='ignore')
#y가 대문자면 4자리, 소문자면 2자리
이제 '발생년월일시' 컬럼은 필요 없으니까 삭제 해줄게요
컬럼 삭제
# 필요 없는 컬럼 삭제
del accident_df['발생년월일시']컬럼 정렬
우리가 추가해 준 두 컬럼은 순서가 마지막으로 들어가요
년도 뒷쪽에 두 컬럼을 넣어주려면 어떻게 해야 할까요?
컬럼 순서가 담긴 리스트를 만들어주세요
# 컬럼 순서 정리 발생년, 발생년월일, 발생시간, ...
# 컬럼명을 리스트로 만들기
col1 = accident_df.columns[-2:].to_list()
col1.reverse()
col2 = accident_df.columns[1:-2].to_list()
col_list = col1 + col2
col_list.insert(0,'발생년') # .insert():0자리에 '발생년' 넣기
accident_df = accident_df[col_list] # 컬럼명이 담긴 리스트를 다시 담아주기
그럼 데이터가 원하는대로 전처리가 다 되었어요!!
처리한 파일을 두고두고 쓰고 싶다면 '저장'을 해야겠죠
accident_df.to_csv('/content/drive/MyDrive/Colab Notebooks/source/2019년 사망 교통사고 전처리_20240704.csv',encoding='utf-8-sig', index=False)다음처럼 .to_csv를 이용하면 csv파일로 저장이 됩니다!
2019년 사망 교통사고 데이터 시각화
이제 자료를 정리했으니 본격적으로 데이터 분석을 해봅시다!
날짜별/시간별 데이터 분석
#px는 데이터 프레임을 통째로 주고 컬럼명을 정해서 출력 가능
fig = px.scatter(accident_df, x = '발생년월일',y='발생시간',
size='사망자수',color = '발생지시도')
fig.show()
시간대별 교통사고 현황
fig = px.bar(accident_df,y='발생시간',x='사망자수',orientation='h')
# 그래프 막대가 누워있게 표현하려면 orientation = 'h'을 꼭 해줘야 해요
fig.show()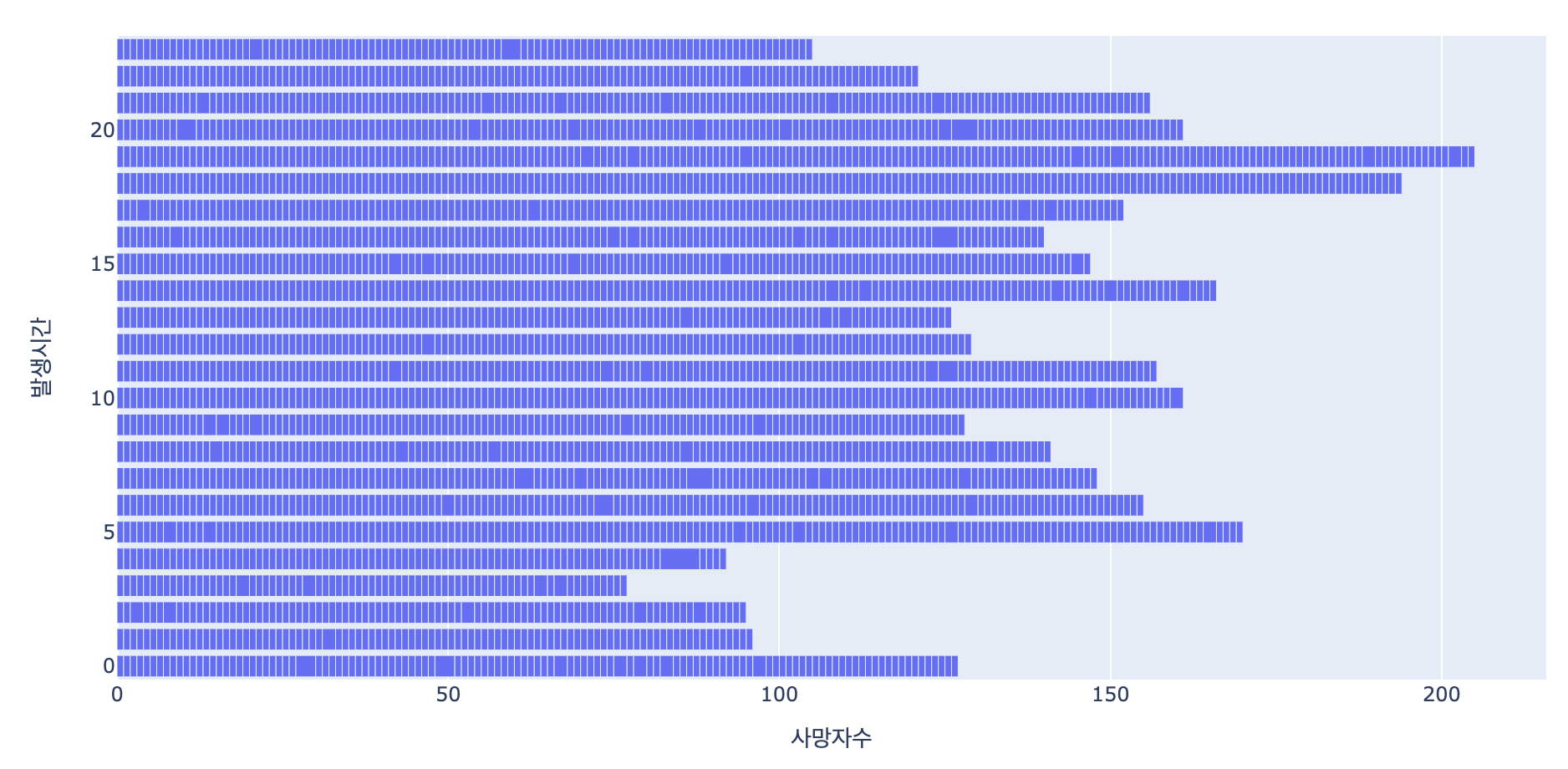
시도별 교통사고 현황
#시,도에 대해서 가나다 순으로 정렬하는 코드에요. unique로 발생지시도 목록을 뽑고 sort로 정렬해요
accident_df['발생지시도'].unique()
location_list = accident_df['발생지시도'].unique()
location_list.sort()
location_listplt.figure(figsize=(10,5))
sns.countplot(accident_df,y='발생지시도',order=location_list)
plt.show()
fig = px.histogram(accident_df, x='사망자수',y='발생지시도',orientation='h',text_auto=True,category_orders={'발생지시도':location_list})
fig.show()
plotly.express 라이브러리와
seaborn 라이브러리를 둘 다 사용해서 해봤어요
차이점을 보시구 비교분석 한 번 해보세요!
plotly.express에서 사망자수를 기준으로 정렬하고 싶을땐 어떡하지?
accident_df['발생지시도'].value_counts().index이 코드를 사용하면 사망자가 많은 순으로 정렬하고 인덱스를 받아주는거에요
value_counts( ) 많이 쓰인답니당~
fig = px.histogram(accident_df, x='사망자수',y='발생지시도',orientation='h',text_auto=True,
category_orders={'발생지시도':accident_df['발생지시도'].value_counts().index})
fig.show()
plt.figure(figsize=(10,5))
sns.countplot(accident_df,x='발생지시도',order=accident_df['발생지시도'].value_counts().index)
plt.show()요일별 교통사고 현황
먼저 plotly.express를 이용해서 그려볼게요
day_list = ['월','화','수','목','금','토','일']
fig = px.histogram(accident_df, x='사망자수',y='요일',orientation='h',
text_auto=True,category_orders={'요일':day_list})
fig.show()시도별 교통사고랑 비슷하지만 쪼~끔 달라요!
y='요일'로 바꿔주시고 order를 월~일까지 있는 리스트로 정렬해줘요
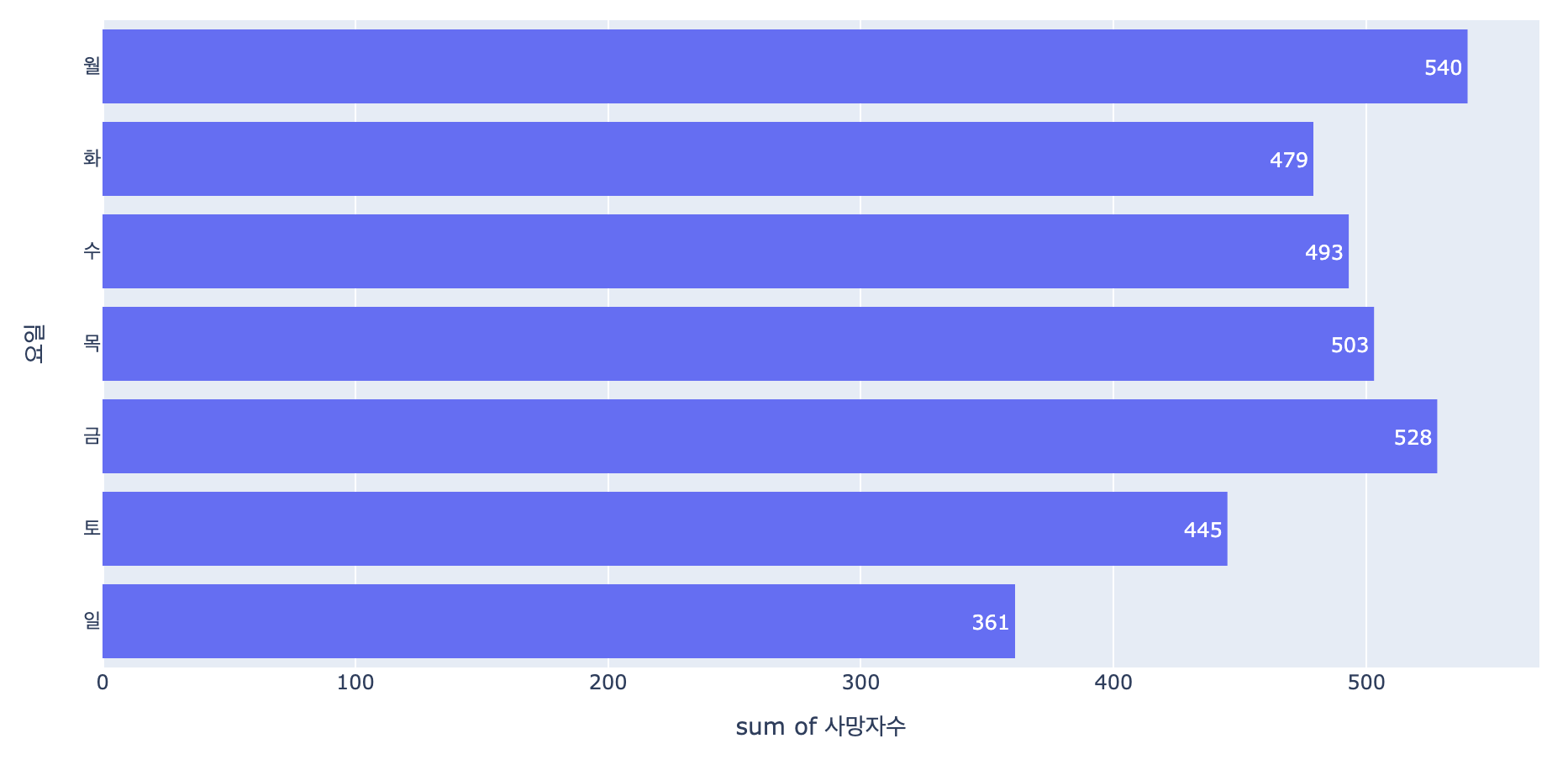
이제 seaborn을 이용해서 그래프를 그려볼까요?
plt.figure(figsize=(10,5))
sns.countplot(accident_df,x='요일', order=day_list)
plt.show()
seaborn 라이브러리에서는 plotlib과 함께 쓰면 더 편해요
plt.figure로 사이즈를 정하고
그래프를 출력해주면 더 깔끔하답니다!
경기도 사망 교통사고 데이터 분석
이번에는 특정 시 · 도 를 기준으로 해볼게요!
저번 글에서 배웠던 특정 데이터만 추출하는 메소드가 있었죠~
gg_df = accident_df.query("발생지시도 == '경기'")
gg_df.info()
=>
--- ------ -------------- -----
0 발생년 608 non-null int64
1 발생년월일 608 non-null datetime64[ns]
2 발생시간 608 non-null int64
3 주야 608 non-null object
4 요일 608 non-null object바로 query 메소드 입니다!
보시면 608건의 경기도 데이터만 들어갔어요.
이제 영역별로 통계를 내볼게요
발생시간별 교통사고 사망자 현황
fig = px.bar(gg_df , x = '사망자수' , y='발생시간',orientation = 'h')
fig.show()
지금 보면 20시, 즉 저녁 8시에 교통사고가 가장 많이 났다는 걸 알 수 있었어요
퇴근 시간 이후에 사고가 가장 많이 났네요
지역구별 교통사고 사망자 현황
fig = px.bar(dj_df,x='사망자수',y='발생지시군구',orientation = 'h')
fig.show()
지금 되게 답답하지 않나요?
'발생지시군구'의 데이터 네임이 짤렸어요 ㅠㅠ
이건 기본 그래프의 높이가 낮아서 그래요.
그럼 높이를 키워볼까요?
fig = px.bar(dj_df,x='사망자수',y='발생지시군구',orientation = 'h', height=800)
fig.show()

너무 커서 짤렸지만... ㅋ쿠큐쿠ㅜㅜ
그래도 이런식으로 높이를 조절할 수 있답니다!
넓이도 마찬가지로 width를 변수로 두면 조정 가능해요!
월별 교통사고 현황
월별로 교통사고를 나눠보고 싶은데!
우리가 월별로 컬럼을 나누진 않았잖아요?
그래서 '발생월' 컬럼을 새로 만들어볼게요!
accident_df['발생월'] = accident_df['발생년월일'].dt.month
dj_df['발생월'] = dj_df['발생년월일'].dt.month이런식으로~ datetime 자료형은 .dt를 이용해서
년,월,일,시간,분 등등 손쉽게 쪼갤 수 있답니다!
#월별 교통사고 전국 vs 경기
fig, axes = plt.subplots(1,2,figsize =(15,5))
plt.suptitle('2019년 월별 교통사고 발생건수 비교')
sns.countplot(data=accident_df, x='발생월', ax=axes[0], order=accident_df['발생월'].value_counts().index)
axes[0].set_title('전국')
sns.countplot(data=gg_df, x='발생월', ax=axes[1], order=gg_df['발생월'].value_counts().index)
axes[1].set_title('경기')
plt.ylim(0, accident_df['발생월'].value_counts().max())
plt.show()
처음 보는 함수가 있을거에요!
바로바로
plt.ylim 함수에요~ 지금 전국과 경기의 y축의 level이 같죠?
이 함수로 두 그래프의 y축을 같게 했답니다
지도를 활용해서 사망 교통사고 현황 분석
여기서는 지금껏 배웠던 것중에 가장 재밌어요!!

(예에에.. 재밌다...)
우선 지도부터 준비해 줄게요
기본 지도 준비하기
#로케이션은 중심좌표 지도는 중심좌표를 기준으로 실시간으로 랜더링 해요
map = folium.Map(location=[37.540705, 126.956764]) # 위도, 경도
map

그럼 이렇게 지도가 나온답니다!
여러분들! 그거 아시나요.,.,?
서울의 중심좌표는 서울시청이에요...!

알고 계셨다면.. 뭐... ㅎㅎ;;
모든 시·도의 중심좌표는 시청 또는 도청이랍니다!
# 사망사고 위치에 CircleMarker 표출
# 사망자수의 size 만큼 Circle size 조정
# CircleMarker 사이즈 = 사망자수 + 부상자수(중상자수 + 경상자수 + 부상신고자수)
# CircleMarker 클릭하면 popup 사고유형 표출
# CircleMarker 사이즈는 실수형 데이터만 취급
# 사망자수, 부상자수의 컬럼의 자료형을 실수로 형변환
gg_df = dj_df.astype({'사망자수' : 'float','부상자수' : 'float'})
gg_df.info()
=>
4 요일 608 non-null object
5 사망자수 608 non-null float64
6 부상자수 608 non-null float64
7 중상자수 608 non-null int64지금 원을 만들어서 지도에 찍어 사고를 표시하고 싶어요.
그렇기 때문에 원의 지름을 정해야 하는데요.
저는 사망자수와 부상자 수를 합한 값을 원의 사이즈로 정했어요
더하려면 실수형으로 나와야 하니까 타입을 바꿔줬어요.
CircleMarker 지도 표출
#1) 지도 준비
map = folium.Map(location=[37.540705, 126.956764]) # 위도, 경도
#2) circleMarker 지도에 표출 -> for문을 이용해서 dj_df에 정보가 있을 때까지 지도에 add
for n in dj_df.index:
# circlemarker 사이즈
cnt = dj_df['사망자수'][n] + dj_df['부상자수'][n]
# 사고 위치 위도, 경도 추출
lat = dj_df['위도'][n]
lng = dj_df['경도'][n]
#지도에 add 하기, 기본 rad가 10임.
folium.CircleMarker(location=[lat,lng],radius =cnt*2,
popup=f"사고유형: {dj_df['사고유형'][n]}<br>사망자수: {dj_df['사망자수'][n]}<br>부상자수: {dj_df['부상자수'][n]}",
color='red',
fill_color='red').add_to(map)조금 어려울 수 있지만 하나씩 쪼개서 보면 이해 할 만 해요!

그럼 그림처럼 원으로 사고지역이 나오고
사망자 수, 부상자 수에 따라 원의 크기가 다르게 출력돼요.
이번주 python강의는 끝!
이제 다음 시간에 만나요!
'ABC 부트캠프' 카테고리의 다른 글
| [11일차] ABC부트캠프 - 데이터 크롤링(네이버 기사 수집 & 시각화) (2) | 2024.07.08 |
|---|---|
| [10일차] ABC 부트캠프 - ESG 강연(배리어프리와 사회적 약자를 위한 따뜻한 기술) (0) | 2024.07.07 |
| [8일차] ABC부트캠프 - 데이터 분석 with Python (실전 예제) (0) | 2024.07.03 |
| [7일차] ABC 부트캠프 - 데이터분석 with Python (pandas) (0) | 2024.07.02 |
| [6일차] ABC부트캠프 - 데이터 분석 with Python (matplotlib) (0) | 2024.07.01 |



